
Copyright © Cay S. Horstmann 2015 
This work is licensed under a Creative Commons Attribution 4.0 International License
val head = <head><title>Fred's Memoirs</title></head>Has type
scala.xml.Elemval items = <li>Fred</li><li>Wilma</li>Is a
scala.xml.NodeSeqx <y
xml"..." instead.scala.xml.Node superclass of all XML node typesElem and Texte is an Elem, e.label is the tag namee.child is the NodeSeq of children (it's child, not children, like in XPath)NodeSeq is a subtype of Seq[Node] with support for XPath-like opsNode extends NodeSeq as a sequence of length 1NodeBuffer
val items = new scala.xml.NodeBuffer items += <li>Fred</li> items += <li>Wilma</li>
NodeBuffer is converted to NodeSeq, don't mutate it any more!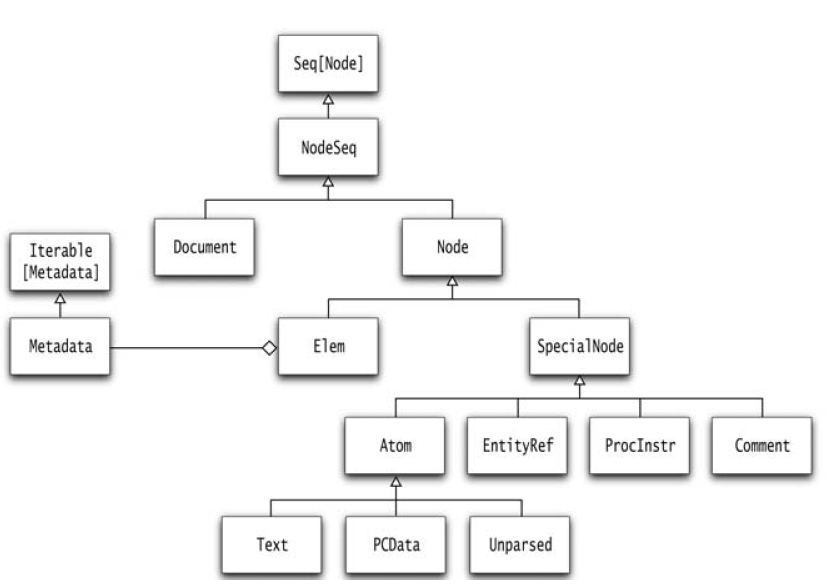
image.attributes gets a map-like key/value association
val image = <img src="logo.jpg" alt="San José State University Logo"/>
val src = image.attributes("src")NodeSeq because it may contain EntityRefimage.attributes.toAttrMap, which yields a Map[String, String]<ul><li>{items(0)}</li><li>{items(1)}</li></ul>
NodeSeq are spliced into the XML. Everything else wrapped into Atom[T]String becomes Atom[String], not Text<ul>{items.map(i => <li>{i}</li>)}</ul>
{ } inside XML, double them:
<h1>The Natural Numbers {{1, 2, 3, ...}}</h1><img src={makeURL(fileName)}/><img src="{makeURL(fileName)}"/>
does not execute the expression in { ... }<table>
{(1 to 10) map (i =>
<tr>
{(1 to 10) map (j => <td>{ i * j }</td>)}
</tr>)}
</table>
NodeSeq whose child contains 100 elementsElem whose child is a NodeSeq of length 10Elem whose child is a NodeSeq of length 100Elem whose descendants include 100 Text nodes\ and \\ with NodeSeq like / and // in XPath
val list = <dl><dt>Java</dt><dd>Gosling</dd>
<dt>Scala</dt><dd>Odersky</dd></dl>
val languages = list \ "dt"
// Yields a NodeSeq of <dt>Java</dt> and <dt>Scala</dt>
doc \ "body" \ "_" \ "li"
\\ locates descendants at any depth:
doc \\ "img"
@ locates attributes:
img \ "@alt"
(<img src="hamster.jpg"/><img src="frog.jpg"/> \\ "@src").text
"hamster.jpgfrog.jpg"<src>hamster.jpg</src><src>frog.jpg</src>NodeSeq("hamster.jpg", "frog.jpg")n match {
case <img/> => ...
}img with any attributes and no children case <li>{_}</li> => ...
case <li>{_*}</li> => ...
case <li>{child}</li> => child.text
case <li>{Text(item)}</li> => item
case <li>{children @ _*}</li> => children.map(...)
children is a Seq[Node] and not a NodeSequl to ol:
import scala.xml._
import scala.xml.transform._
val rule1 = new RewriteRule {
override def transform(n: Node) = n match {
case e @ <ul>{_*}</ul> => e.asInstanceOf[Elem].copy(label = "ol")
case _ => n
}
}RuleTransformer:
val transformed = new RuleTransformer(rule1, rule2, rule3).transform(root);
copy makes a copy of an Elem, modifying the tag or children:
list.copy(child = list.child ++ <li>Another item</li>)
% to change an attribute:
image % Attribute(null, "alt", "An image of a hamster", Null)
val root = scala.xml.XML.loadFile("myfile.xml")ConstructingParser preserves comments, CDATA sections, and optionally white space:
import scala.xml.parsing._
val parser = ConstructingParser.fromFile(new File("myfile.xml"), preserveWS = true)
val root = parser.document.docElem
val parser = new XhtmlParser(scala.io.Source.fromFile("myfile.html"))
val doc = parser.initialize.documentXML.save("myfile.xml", root)
XML.write(writer, root)
Each has different options—check the scaladoc
unit11. Right-click on the project in the tree display at the left, select Properties → Java Build Path → Libraries → Add External JARs, then locate to the directory where the Scala IDE is installed, go to its plugins directory, and pick org.scala-lang.modules.scala-xml_1.0.2.jar.images.sc. Now read a web page:
import scala.xml._
import scala.xml.parsing._
val source = scala.io.Source.fromURL("http://horstmann.com/index.html")
val parser = new XhtmlParser(source)
val doc = parser.initialize.document
What do you get?\\, find all img tags. How many are they?src attributes. (Hint: \\ returns a NodeSeq.)null come from? (If you can't find it, don't worry—there will be a homework assignment to help.)What did the loop of the preceding problem do? Print all characters in the string s *Print the string s in reverse order Print every other character in the string s Count the number of characters in sYou'd like them to look like this:
class and onclick attributes need to be put where?
script and link tags at the beginning of these slides to see how the JS/CSS are included.quiz.txt into some known location, such as ~/Downloads with the sample question above.unit11 project, make a worksheet quizwriter.sc:
import scala.xml._
val source = scala.io.Source.fromFile("~/Downloads/quiz.txt", "UTF-8")
val lines = source.getLines.toVector
val i = lines.lastIndexWhere(_.trim.length == 0)
val questionText = lines.take(i).map(l => <p>{l}</p>)
val doc = <html>...</html>
XML.save("~/Downloads/quiz.html", doc)
Look at the file in the browser. Does it work? <body> <h1>Main heading</h1> Introduction <h2>Subheading</h2> Contents <h2>Another Subheading</h2> More Contents </body>But the contents of a subsection was not nested in the contents of a section, unless you chose to include it in a
div. HTML 5 suggests that you use the section element to mark the semantics:
<body>
<h1>Main heading</h1>
Introduction
<section>
<h2>Subheading</h2>
Contents
</section>
<section>
<h2>Another Subheading</h2>
More Contents
</section>
</body>
We'd like to achieve that transformation. Why is it harder than the example of replacing all ul with ol?
child node sequence of body. We could loop over it, but that wouldn't be the functional way. Instead, we'd like to group it into a sequence of sequences:
h2h2 up to, but not including, the secondh2 to the endsection.
Seq. Which ones produce a sequence, iterator, or map of sequences?
def splitWhere[T](xs: Seq[T])(p: (T) => Boolean): Seq[Seq[T]]so we can call
val splits = splitWhere(body.child)(...)
val intro = splits(0)
val section1 = <section>{splits(1)}</section>
What do you need for the ...?
splitWhere for testing. Don't code like that! You'll get to produce a nicer version in the homework.
def splitWhere[T](xs: Seq[T])(p: (T) => Boolean): Seq[Seq[T]] = {
// Don't code like this!
val result = new scala.collection.mutable.ArrayBuffer[scala.collection.mutable.ArrayBuffer[T]]()
result += new scala.collection.mutable.ArrayBuffer[T]()
for (x <- xs) {
if (p(x)) result += new scala.collection.mutable.ArrayBuffer[T]()
result.last += x
}
result
}
You'll also need to figure out how to get to the body. Remember that doc \\ "body" is a NodeSeq.
val sections = splits.tail.map(s => ...) val newBody = ...
{kind=link}
{kind=link}
{kind=link}